ARQUITECTURA LAMBDA Y KAPPA
¿Qué son las arquitecturas de Big Data?
Las arquitecturas de Big Data son modelos de diseño estructural que definen la forma en que los sistemas capturan, almacenan, procesan y analizan grandes volúmenes de datos, permitiendo trabajar tanto con datos históricos como con datos en tiempo real.
Estas arquitecturas son fundamentales para garantizar:
-
Escalabilidad
-
Alta disponibilidad
-
Procesamiento eficiente
-
Análisis oportuno de la información
Entre las arquitecturas más representativas se encuentran:
-
Arquitectura Lambda
-
Arquitectura Kappa
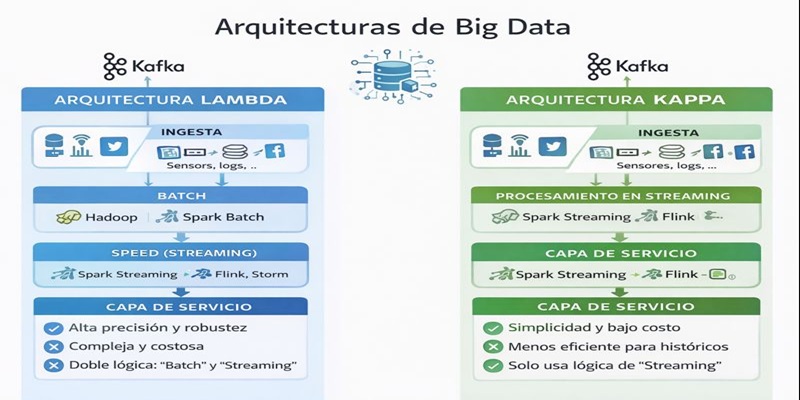
Arquitectura lambda
La Arquitectura Lambda es un modelo de procesamiento de datos que combina dos rutas de análisis para obtener resultados precisos y de baja latencia. Está diseñada para manejar grandes volúmenes de datos distribuidos, equilibrando exactitud y velocidad.
La arquitectura Lambda divide el flujo de datos en dos caminos:
-
Batch (por lotes):
Procesa datos históricos almacenados, ofreciendo resultados altamente precisos, aunque con mayor tiempo de procesamiento. -
Speed (tiempo real):
Procesa datos en streaming de forma inmediata, permitiendo respuestas rápidas, aunque con menor nivel de exactitud inicial.
Ambos resultados se integran posteriormente en una capa de servicio, que entrega la información final al usuario.
Capas de la Arquitectura Lambda
1. Capa de Ingesta
-
Recibe datos provenientes de diversas fuentes.
-
Puede manejar grandes volúmenes y alta velocidad de entrada.
-
Ejemplos de fuentes: sensores IoT, registros de sistemas, redes sociales.
-
Herramientas comunes: Apache Kafka, Apache Flume.
2. Capa Batch
-
Procesa datos históricos almacenados.
-
Utiliza procesamiento distribuido.
-
Produce resultados completos y confiables.
-
Herramientas: Hadoop, Apache Spark (Batch).
3. Capa Speed (Streaming)
-
Procesa datos en tiempo real o casi real.
-
Genera resultados rápidos para eventos recientes.
-
Herramientas: Spark Streaming, Apache Flink, Apache Storm.
4. Capa de Servicio
-
Combina los resultados del procesamiento batch y streaming.
-
Expone la información a los usuarios finales.
-
Ejemplos: dashboards, APIs, sistemas de reportes.
| Ventajas | Desventajas |
| Alta precisión + baja latencia | Arquitectura compleja |
| Ideal para análisis complejos | Doble lógica (batch y streaming) |
| Muy robusta | Mayor costo y mantenimiento |
Arquitectura kappa
La Arquitectura Kappa surge como una alternativa simplificada a Lambda. Se basa en la idea de que todo el procesamiento de datos puede realizarse mediante streaming, incluso cuando se trata de datos históricos.
En este modelo, los datos se consideran como eventos inmutables almacenados en un sistema de mensajería, que pueden reprocesarse cuando sea necesario.
Capas de la Arquitectura Kappa
1. Ingesta de datos
-
Captura flujos continuos de eventos.
-
Los datos se almacenan de forma persistente.
-
Herramienta principal: Apache Kafka.
2. Procesamiento en Streaming
-
Un único motor de procesamiento maneja todos los datos.
-
Se aplica la misma lógica tanto para datos nuevos como históricos.
-
Herramientas: Spark Streaming, Apache Flink.
3. Capa de Servicio
-
Presenta los resultados procesados.
-
Permite su consumo mediante aplicaciones, dashboards o APIs.
| Ventajas | Desventajas |
| Arquitectura simple | Menos eficiente para análisis históricos muy grandes |
| Una sola lógica de procesamiento |
Puede ser más lento para consultas de datos históricos en comparación con los sistemas optimizados por lotes. |
| Ideal para tiempo real |
Almacenar principalmente datos sin procesar puede aumentar el riesgo de pérdida de datos si no se cuentan con estrategias de respaldo sólidas. |
| Menor costo de mantenimiento |
Garantizar un procesamiento exactamente una sola vez puede ser más complejo y desafiar la consistencia de los datos. |
CONCLUSIÓN
La Arquitectura Lambda ofrece una solución poderosa para escenarios que requieren alta precisión y análisis histórico profundo, mientras que la Arquitectura Kappa prioriza la simplicidad y el procesamiento en tiempo real. La elección entre ambas depende de los requerimientos del sistema, el volumen de datos y la necesidad de análisis histórico.
