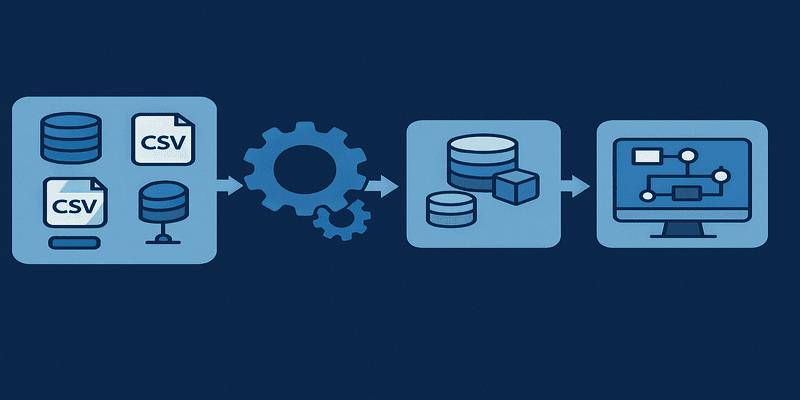
¿Qué es un Pipeline en Big Data?
Un pipeline de Big Data es un conjunto de procesos automatizados y escalables diseñados para manejar datos a gran escala, ya sea en lotes (batch) o en tiempo real (streaming).
Estos procesos se ejecutan en sistemas distribuidos, capaces de procesar volúmenes masivos, con alta variedad de fuentes y con requisitos de velocidad y resiliencia.
Fases típicas de un pipeline de Big Data
Un pipeline de Big Data suele estar compuesto por las siguientes etapas:
1. Ingesta de datos
Aquí los datos son recolectados desde múltiples fuentes:
- Bases de datos relacionales o NoSQL
- APIs externas
- Archivos (CSV, JSON, Parquet)
- Sensores IoT o logs de aplicaciones
- Streams de eventos (Kafka, MQTT)
Herramientas comunes:
Apache Kafka, Apache Flume, Apache NiFi, AWS Kinesis
2. Procesamiento de datos
Dependiendo del caso de uso, el procesamiento puede ser:
- Batch: para grandes volúmenes acumulados
- Streaming: para datos en tiempo real
Se realizan transformaciones como limpieza, agregaciones, joins, detección de patrones, enriquecimiento, etc.
Herramientas comunes:
Apache Spark, Apache Flink, Apache Beam, Databricks
3. Almacenamiento de datos
Una vez procesados, los datos deben almacenarse para su posterior análisis o consumo por otros sistemas.
- Data Lakes: para almacenamiento crudo y flexible (Parquet, ORC)
- Data Warehouses: para datos estructurados y analíticos
- Bases NoSQL: para consultas rápidas y aplicaciones de baja latencia
Herramientas comunes:
Amazon S3, Google Cloud Storage, HDFS, Snowflake, BigQuery, Cassandra
4. Orquestación del pipeline
La ejecución de los diferentes pasos del pipeline debe estar coordinado, con control de errores, dependencias y monitoreo.
Herramientas comunes:
Apache Airflow, Dagster, Prefect
5. Visualización y análisis
Los datos procesados son utilizados por:
- Herramientas de BI (Business Intelligence)
- Dashboards en tiempo real
- Modelos de machine learning
- Aplicaciones empresariales
Herramientas comunes:
Power BI, Tableau, Apache Superset, Jupyter, Looker
Ventajas de un pipeline bien diseñado en Big Data
- Escalabilidad automática
- Reducción de errores humanos mediante automatización
- Tiempos de respuesta más rápidos
- Alta resiliencia ante fallos del sistema
- Capacidad de integrar datos heterogéneos en tiempo real
CONCLUSIÓN
Un pipeline de Big Data no es solo una secuencia de pasos para mover datos, sino una infraestructura crítica para escalar y automatizar procesos en entornos donde el volumen, la velocidad y la variedad de los datos superan las capacidades tradicionales. Diseñar un pipeline eficiente requiere entender la arquitectura distribuida, elegir las herramientas adecuadas y mantener una visión integral del ciclo de vida de los datos. Ya sea que estés comenzando con un pequeño flujo de eventos o escalando a petabytes de información, dominar los principios de un pipeline de Big Data es esencial en el mundo de los datos modernos.

- Debes estar logueado para realizar comentarios