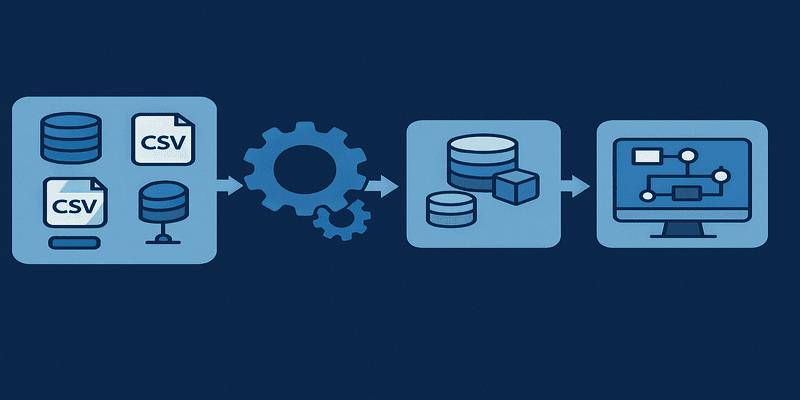
Un pipeline de Big Data es una cadena automatizada y escalable de procesos que permite la ingesta, procesamiento, almacenamiento y análisis de grandes volúmenes de datos en tiempo real o por lotes. Utiliza arquitecturas distribuidas y herramientas especializadas para manejar datos masivos con velocidad y resiliencia. Su correcta impl...

Apache Hadoop y Apache Spark son dos de las tecnologías más populares en el mundo de Big Data, pero tienen diferencias fundamentales. Mientras que Hadoop es conocido por su robustez en el procesamiento por lotes, Spark destaca por su velocidad y flexibilidad, al permitir tanto procesamiento en tiempo real como en lotes. La elección e...
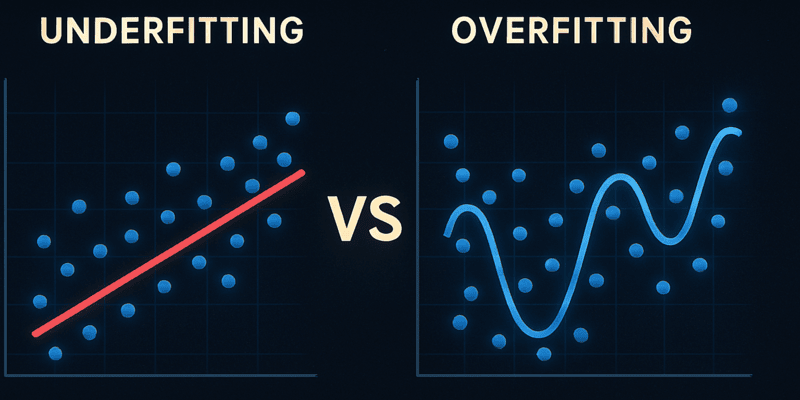
El underfitting y el overfitting son problemas comunes en el aprendizaje automático que afectan la capacidad de un modelo para generalizar. El underfitting ocurre cuando el modelo es demasiado simple y no logra captar patrones importantes, mientras que el overfitting sucede cuando se ajusta en exceso a los datos de entrenamiento, inc...

El aprendizaje por refuerzo (Reinforcement Learning o RL) es una subdisciplina del aprendizaje automático donde un agente aprende a actuar en un entorno tomando decisiones que le permitan maximizar una recompensa acumulada. Este enfoque se basa en el principio de prueba y error y se inspira en cómo los humanos y animales aprenden de ...

En un ámbito de IA, las CNN son ideales para procesar datos espaciales como imágenes y vídeos, extrayendo patrones visuales clave. En cambio, las RNN sobresalen en tareas secuenciales como el procesamiento de texto o la predicción de series temporales, aprendiendo de contextos anteriores. La elección entre ambas depende de la natural...

Machine Learning es una rama de la IA que permite a las máquinas aprender de los datos mediante algoritmos. Deep Learning es un tipo de Machine Learning que utiliza redes neuronales profundas para resolver tareas complejas como visión, lenguaje y audio. La diferencia está en la profundidad del modelo, la cantidad de datos y el poder ...

TinyML permite ejecutar inteligencia artificial en dispositivos muy pequeños, como sensores y microcontroladores, sin necesidad de conexión a internet. Esto mejora la privacidad, la velocidad y el consumo energético, haciéndolo ideal para salud, agricultura y hogares inteligentes. Solo se necesita hardware económico como Arduino o ES...