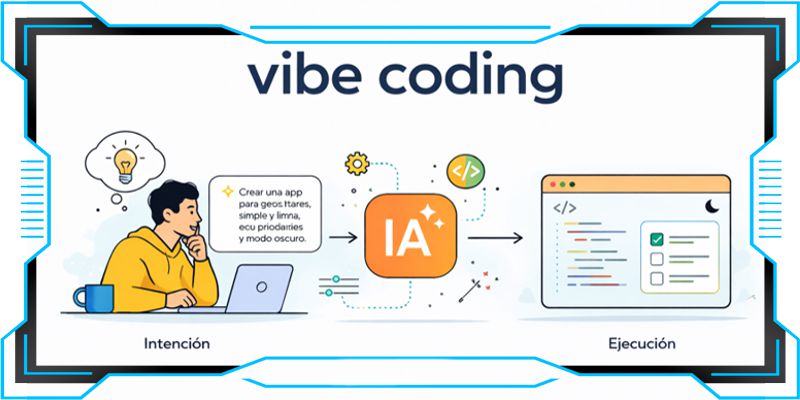
El modo de desarrollar software está cambiando mediante la adopción del modelo de creación basada en la intención. Este enfoque centrarse en la lógica y el propósito del producto, mientras los sistemas de inteligencia artificial ejecutan la infraestructura técnica. A día de hoy, esta tendencia acelera los ciclos de producción de mane...
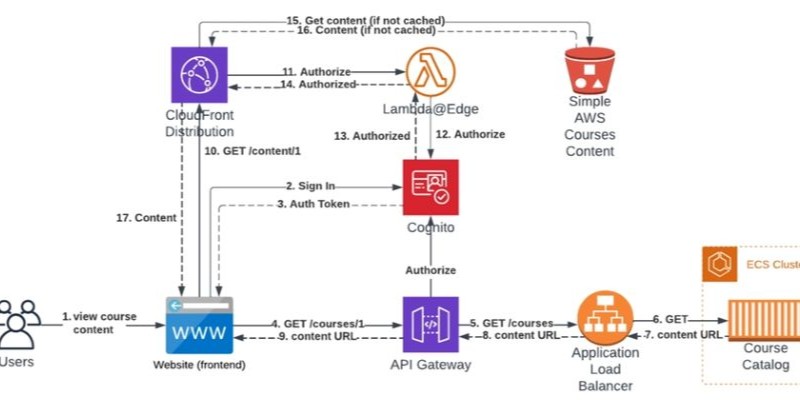
Proteger contenido en Amazon S3 es fundamental cuando se trabaja con aplicaciones que requieren autenticación. En lugar de exponer archivos públicamente, es posible utilizar servicios como CloudFront, Cognito y Lambda@Edge para controlar quién accede a los recursos. Esta arquitectura permite que solo usuarios autenticados puedan cons...

Ejecutar modelos de lenguaje y visión de vanguardia directamente en tu hardware ya no es cosa del otro mundo. Ollama se consolida como la infraestructura definitiva para esta transición hacia la IA local, que te permite eliminar costos de suscripción, garantizar la privacidad absoluta de tus datos y operar sin conexión a internet. En...

Durante décadas, el estudio del cerebro se basó en observar neuronas individuales o pequeñas redes neuronales en laboratorio. Hoy, gracias a los avances en neurociencia computacional y simulación digital, los científicos han logrado algo que antes parecía ciencia ficción: reconstruir y ejecutar digitalmente el cerebro completo de una...

Las estrategias de renderizado determinan cómo se genera y muestra el contenido de una aplicación web. Dos enfoques comunes son CSR (Client-Side Rendering) y SSR (Server-Side Rendering). Cada uno tiene ventajas y desventajas en términos de rendimiento, experiencia de usuario y posicionamiento en buscadores. Elegir la estrategia adecu...

La automatización de navegadores ha pasado de ser una tarea de pruebas de software a convertirse en la infraestructura que sustenta la ejecución de agentes de inteligencia artificial y la extracción de datos a gran escala. Puppeteer, mantenido por el equipo de Chrome DevTools, representa el estándar de facto para el control programát...

Durante años, la Inteligencia Artificial fue vista principalmente como una herramienta para automatizar tareas, analizar datos o mejorar la productividad empresarial. Sin embargo, en los últimos años su papel ha evolucionado hasta convertirse en un componente estratégico dentro de la planificación militar. Uno de los casos más recien...